Did you ever wonder how Spotify, Tidal or YouTube work? Why are they suggesting a song to you?. Sometimes the suggestions are quite good. Come with we on a visual journey through AI playlists.
Author
Dominik Lindner
Published
July 15, 2025
1 Playing DJ
I recently got to play DJ at a private party. Usually, this involves endless hours of listening through songs. You then try to figure out what track fits best where, how to build energy, and what to avoid. It is like a radio DJ with a static playlist. Creating a static playlist that matches the vibe at different times throughout the night can be tough work.
But now we have AI. Everything is soo easy.
That was my state of mind, when I started with Deej-AI.
My idea was simple: tell the AI what music I like and let it handle the playlist. With clear instructions provided by the creator in the repository, I anticipated having my perfect playlist ready in no time.
1.1 Playlist creation with Deej-AI
I started by selecting a few hundred songs I love. I did not care much about the order or proportion of style, hoping the software would seamlessly fill in the gaps. Running the software quickly generated playlists, which looked okayish at a first glance. Looking deeper, imperfections began to show. As I preferred no song repetitions, the playlist noticeably deteriorated towards the end when the algorithm ran out of optimal matches.
This highlighted a crucial issue of Deej-AI: the lack of global optimization. Deej-AI could suggest suitable songs individually but struggled to maintain consistency and match the overall mood progression throughout the evening. Think of a good mixtape or a carefully curated DJ playlist. The AI creation was the opposite.
Respecting different times of day and specific moods was impossible due to the absence of a robust global layout editor. Even though the software offered gap-filling functionality, it still required explicit instructions about what was missing. In the end, creating a truly seamless playlist still required significant manual effort.
1.2 Why did the computer pick song A over song B?
Despite the lack of features, the picks sometimes pleasantly surprised me; sometimes just surprised. This curiosity led me deeper: why exactly was one song selected over another?
In this article, we’ll explore these choices through three lenses:
We will examine our data at three different scales
Macro-level with t-SNE visualization: to reveal groups of songs and overall patterns in the playlist.
Meso-level with Grad-CAM: highlighting crucial parts of audio spectrograms that influenced song selection.
Micro-level with Integrated Gradients: examining the precise contribution of individual audio features.
By dissecting these layers of explainability, I’ll show how your favourite music app works on auto-listening. I hope this is not only valuable for developers, but anybody wondering about why he often ends up with mainstream music on YouTube .
2 Music, just another form of Data
Before we dive into the tools, let’s first clarify what our data looks like. In the following, we look at metadata, audio and embeddings.
2.1 Theme metadata
To help the tool generate better playlists, I divided the day into two distinct segments: a calm part and a more energetic, danceable part. We’ll store this information as metadata and revisit it later in our analysis.
We note which song is in which sublist, as we will require this later.
Code
import csvfrom pathlib import Pathimport pandas as pddef create_manifest():withopen("/app/data/raw-previews/explainabletrack_manifest.csv", "w", newline='') as f: writer = csv.writer(f) writer.writerow(["filename", "theme"])for theme_dir in Path("/app/data/raw-previews/separate").iterdir():if theme_dir.is_dir(): theme = theme_dir.namefor audio_file in theme_dir.glob("*.mp3"): writer.writerow([audio_file.name, theme])
create_manifest()
We now have a table with data, also called tabular data. Your music provider has much bigger tables with a lot more columns (genre, speed, mood, …). For simplicity, we restrict ourselves. Let’s look at the data.
theme
party 129
ruhig 116
Name: count, dtype: int64
NotePaths in this notebook
I use a dockerized version of Deej-Ai, which can be found on my GitHub. Therefore, paths are inside the docker, this is why paths sometimes start with /app and sometimes with /opt.
2.2 Audio data
We are going to study sound signals. Sound is usually analyzed with the help of a spectrogram. While a lot more complex models exist, spectrogram can be just processed as images. This allows us to a simple classification analysis with something as simple as Resnet model.
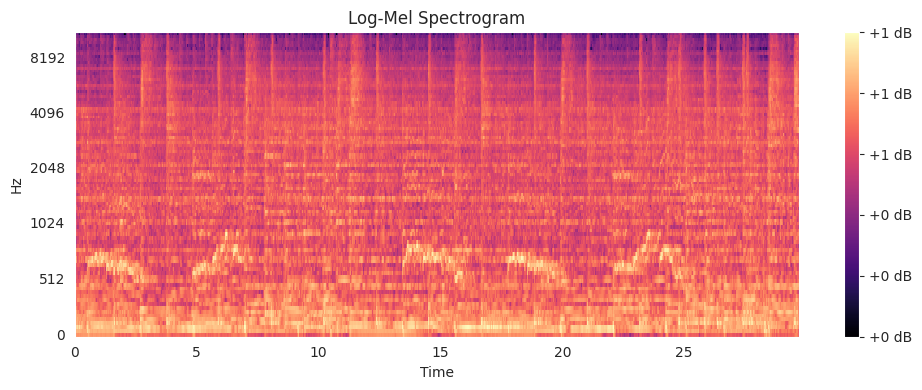
The following picture shows a spectrogram. On the x-axis is the time. The y-axis shows the frequencies. The color is the amplitude of the wave form at this frequency and time.
Code
import librosaimport librosa.displayimport matplotlib.pyplot as pltimport numpy as np# Load audiofilename ='/app/data/raw-previews/combined/Purple Rain - Prince.mp3'y, sr = librosa.load(filename, sr=22050)# Create log-Mel spectrogram, this converts the waveform into a picturen_fft =2048hop_length =512n_mels =96S = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=n_fft, hop_length=hop_length, n_mels=n_mels)log_S = librosa.power_to_db(S, ref=np.max)# normalize the spectogram for further processinglog_S = (log_S - np.min(log_S)) / (np.max(log_S) - np.min(log_S))plt.figure(figsize=(10, 4))librosa.display.specshow(log_S, sr=sr, hop_length=hop_length, x_axis='time', y_axis='mel')plt.colorbar(format='%+2.0f dB')plt.title("Log-Mel Spectrogram")plt.tight_layout()plt.show()
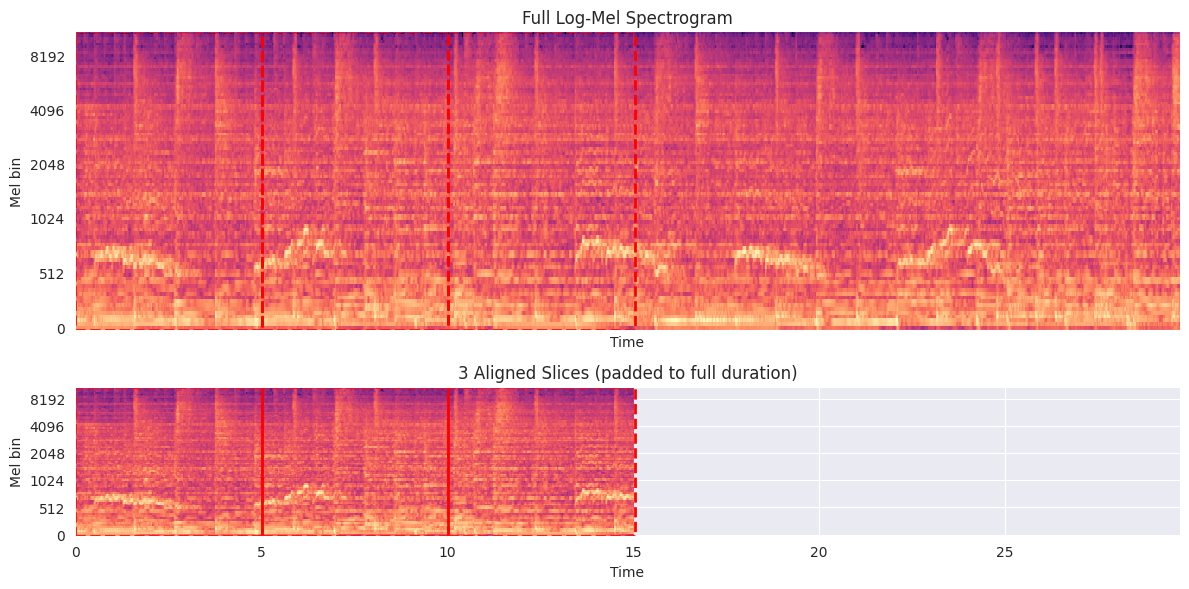
2.2.1 Slicing images
We use spectrogram images to classify the songs. The procedure is identical to your favourite bear or chesse classifier. However, classifying the full spectrogram of one song as a whole is often not very helpful. The songs are usually defined by local features. We either need a more complex model than a CNN, or we reduce the data the CNN sees. In practice, the latter option means we are going to slice the image.
For the study, we use spotify track previews. They usually provide a good sample of the track itself. A more comprehensive analysis would study the whole track and respect intra-track variation.
Let’s slice a track.
def slice_image(slice_size=216, stride=216): slices = [] starts_sec = []for start inrange(0, log_S.shape[1] - slice_size +1, stride): end = start + slice_size slices.append(log_S[:, start:end]) start_sec = start * hop_length / sr end_sec = end * hop_length / sr starts_sec.append((start_sec, end_sec))return slices, starts_secslices, starts_sec = slice_image()print("Number of slices", len(slices))
Number of slices 5
Let’s create a side-by-side view of full spectrogram and slices
Code
num_slices_to_show =3fig, axs = plt.subplots(2, 1, figsize=(12, 6), gridspec_kw={'height_ratios': [2, 1]}, sharex=True)## Plot full spectrogramlibrosa.display.specshow(log_S, sr=sr, hop_length=hop_length, x_axis='time', y_axis='mel', ax=axs[0])axs[0].set_title("Full Log-Mel Spectrogram")axs[0].set_ylabel("Mel bin")# Overlay slicesfor i inrange(min(num_slices_to_show, len(slices))): start, end = starts_sec[i] axs[0].axvspan(start, end, edgecolor='red', facecolor='none', lw=2, linestyle='--')# Slice image## Slices stitched together horizontally, padded to full time widthslice_canvas = np.zeros_like(log_S) * np.nan # fill with NaNsfor i inrange(min(num_slices_to_show, len(slices))): start_frame =int(starts_sec[i][0] * sr / hop_length) slice_data = slices[i] slice_canvas[:, start_frame:start_frame + slice_data.shape[1]] = slice_datalibrosa.display.specshow(slice_canvas, sr=sr, hop_length=hop_length, x_axis='time', y_axis='mel', ax=axs[1])for i inrange(min(num_slices_to_show, len(slices))): start, end = starts_sec[i] axs[1].axvspan(start, end, edgecolor='red', facecolor='none', lw=2, linestyle='--')axs[1].set_title(f"{num_slices_to_show} Aligned Slices (padded to full duration)")axs[1].set_ylabel("Mel bin")plt.tight_layout()plt.show()
Finally, let’s define a function for slicing which we will be using later.
def mp3_to_slices(path): N_MELS =96 SLICE_SIZE =216# must match model input y, sr = librosa.load(path, sr=22050) S = librosa.feature.melspectrogram(y=y, sr=22050, n_fft=2048, hop_length=512, n_mels=N_MELS, fmax=sr /2) x = np.ndarray(shape=(S.shape[1] // SLICE_SIZE, N_MELS, SLICE_SIZE, 1), dtype=float)# we use the original code to get the same input batch sizeforsliceinrange(S.shape[1] // SLICE_SIZE): log_S = librosa.power_to_db(S[:, slice* SLICE_SIZE: (slice+1) * SLICE_SIZE], ref=np.max)if np.max(log_S) - np.min(log_S) !=0: log_S = (log_S - np.min(log_S)) / (np.max(log_S) - np.min(log_S)) x[slice, :, :, 0] = log_Sreturn x
2.3 Embeddings
Instead of working with the spectrogram images in the model, the author of Deej-AI has done something a little bit more complex. He was not interested in knowing which song sounds similar to another, but which songs are usually played together. From this knowledge, he inferred that similar sounding new songs could be also played together with songs in the database.
The understanding of song lyrics and context is implicit in the playlists.
He therefore first encoded many playlists and then matched the spectrograms against this in another training.
The complete Training Inference Pipeline can be visualized like this.
---
format:
html:
mermaid:
theme: neutral
---
flowchart TB
%% === Training #1: Track2Vec ===
subgraph T1[Training #1: Track2Vec]
A1[Audio Files] --> |Organize| B1[Playlists]
B1 --> |Train Track2Vec| C[100D Embeddings]
end
%% === Training #2: Mp3ToVec ===
subgraph T2[Training #2: Mp3ToVec]
D1[Audio Files] -->|Convert & Slice| E1[Log-Mel Spectrograms]
C --> |Use| F1[Embeddings as Labels]
E1 --> E2[Training Input]
F1 --> E2[Training Input]
E2 --> |Train with Cosine Similarity Loss| G1[CNN with 100D Output]
end
%% === Inference ===
subgraph INF[Inference]
I1[Audio Files] --> |Convert & Slice| I2[Log-Mel Spectrograms]
G1 --> |Use| I3[Inference Model]
I2 --> I4[Inference Input]
I3 --> I4[Inference Input]
I4 --> |run model| I5[100D Embeddings]
I6[Query Idx] --> |Cosine Similarity to Find Similar Songs To Query| I7[Best Next Song]
I5 --> I6
end
subgraph t[Training]
T1
T2
end
Instead of using strings as Labels, the embeddings from the Spotify playlist-based Training act as such. Therefore, it is better to speak of dependent variable \(y\). Our labels have the dimension of 100. The second network is a standard classification.
During inference, the predicted output for every spectrogram is a 100D vector. The spectrogram acts as features \(X_{inf}\). In a final step, we rank songs by the best fit to our query.
To answer our questions “Why was song A chosen?” we only need to analyze the inference related to training #2.
We already had a look at \(X\). Now let’s look at the dependent variable \(y\).
3 T-SNE for high dimensionality data.
We are interested in visualizing our labels. I ran the embedding creation in Deej-Ai with MP3ToVec. This is done via model.predict(x). Where \(x\) are the slices we defined earlier. The data was then stored.
import picklefilenames = ['/opt/project/data/raw-previews/combined/'+ f for f in manifest['filename']]withopen("/app/data/pickles/combined/mp3tovecs/mp3tovec.p", "rb") as f: mp3tovecs = pickle.load(f)X = np.vstack([mp3tovecs[f] for f in filenames if f in mp3tovecs])
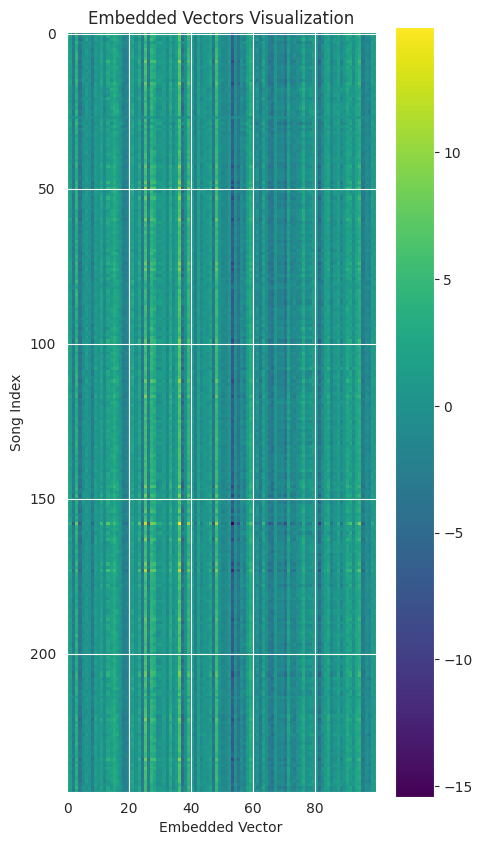
The issue, the data is of the form 100D for each file. How to visualize this. A straightforward approach would be a matrix plot.
From this we can actually not see much. Only that many dimensions are characteristic in their value (vertical lines)
We need to reduce the dimensions to plot this data in a scatter plot. T-distributed stochastic neighbor embedding (TNSE) is a popular dimensionality reduction technique. You can read more on wikipedia. But as with any complex method, there are some caveats. A nice article about the limitations is in distill.pub.
3.1 T-SNE Limitations TL;DR;
Distances are not reliable: Global structure is often distorted; distances between clusters are meaningless.
Cluster sizes are misleading: Size/shape doesn’t reflect actual data density or variance.
Clusters can be artifacts: t-SNE can create apparent groupings even from random data.
Sensitive to hyperparameters: Perplexity, learning rate, and iterations drastically affect results.
Non-deterministic: Results vary with different random seeds; always run multiple times.
No generalization: Can’t project new data without retraining (non-parametric).
Slow on large datasets: Scales poorly; approximations or UMAP may be better.
3.2 T-SNE Best Practice TL;DR;
Tune parameters carefully.
Run multiple times to check stability.
Don’t trust distances, cluster sizes, or shapes.
Use it for exploration, not clustering or quantification.
Compare with PCA, UMAP, or other embeddings.
In short, the main issue is the sensitive to the hyperparameters. A recent paper, Gove et al. 2022, came up with a comprehensive study. In contrast to a previous study Kobak and Berens, 2019, the authors found no dependence on the size of the dataset (previously 1% of dataset size). The previous results translate to perplexity of 2.5. This means any point is just influenced by 2 other points. This often overstressed the local structure. Instead, we focus on the newer magic recipe.
Lost global shape? → double learning-rate or bump perplexity (never past 16).
Over-compressed? → lower exaggeration or learning-rate.
Big data (≫20 k points): try perplexity ≈ n/100 and lr ≈ n/12.
3.4 T-SNE for the playlist data
Let’s apply these findings to our data. To check the stability of the result, we treat this as a convergence issue and write a function that checks the solution for stability.
from sklearn.manifold import TSNEdef tsne_until_converged( X, step_iter=250, max_iter=10000, tol=1e-3, random_state=42, verbose=True, perplexity=5, learning_rate=10, exaggeration=1): n = X.shape[0] common =dict( n_components=2, perplexity=perplexity, learning_rate=learning_rate, early_exaggeration=exaggeration, init="pca", random_state=random_state, verbose=False, )# we always start at 250 total_iter =250 tsne = TSNE(max_iter=total_iter, **common) Y = tsne.fit_transform(X) history = [] prev = Y.copy()while total_iter < max_iter: total_iter += step_iter tsne = TSNE( max_iter=total_iter,**common, ) Y = tsne.fit_transform(X)# Check the stability delta = np.linalg.norm(Y - prev, axis=1).mean() history.append(delta)if verbose:print(f"[{total_iter + step_iter} iters] mean move = {delta:.6f}")if delta < tol:if verbose:print("✓ Converged")break prev = Y.copy()return Y, history, total_iter
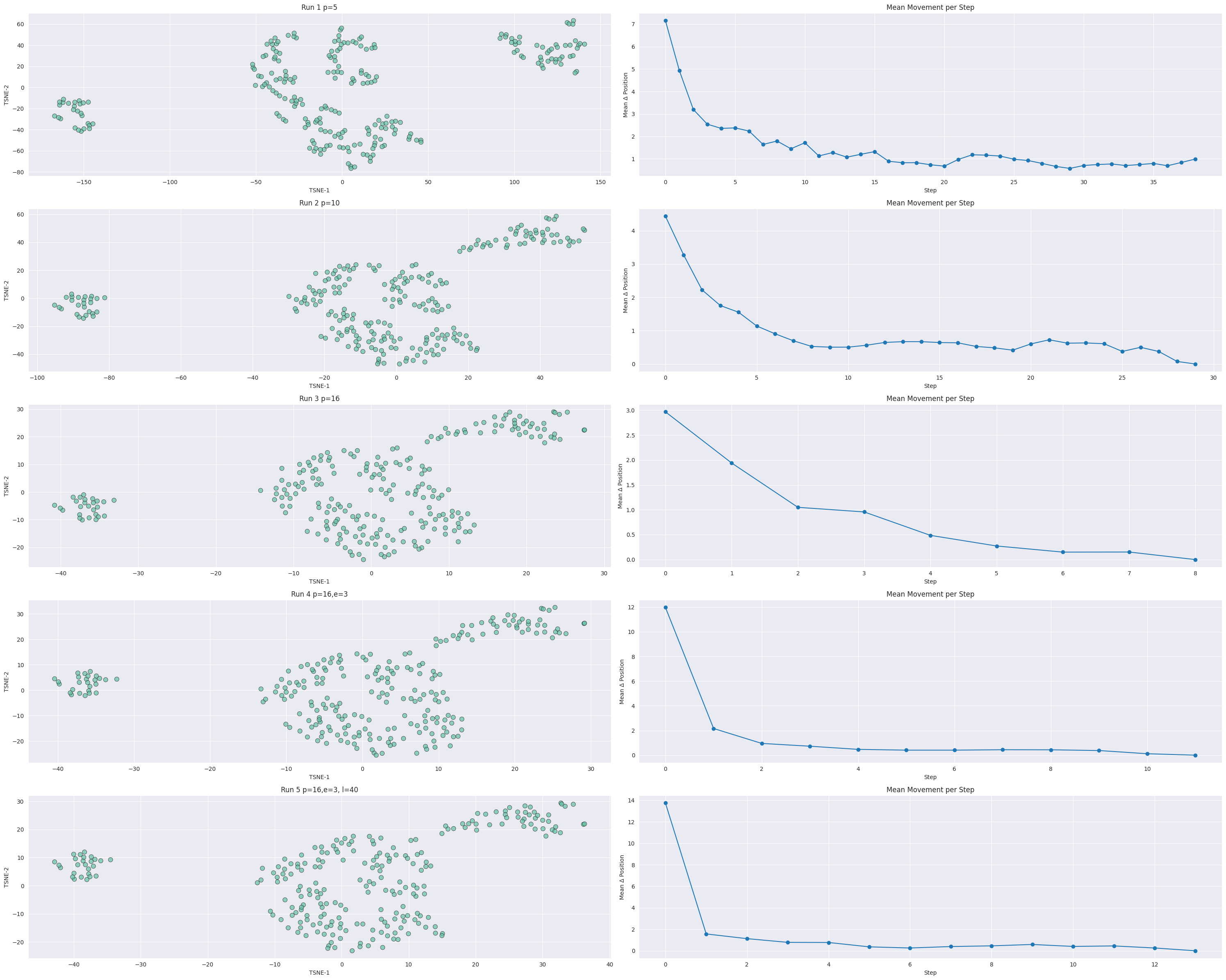
Here are my iterations, which I did follow the magic recipe.
There is not much variation. There are three distinctive groups in all pictures. The standard setting in run2 leads to vertically squeezed distribution. The result in this respect seems better in run 5, with early exaggeration and increased learning rate.
3.5 Can we see two groups (party and quite) in the data?
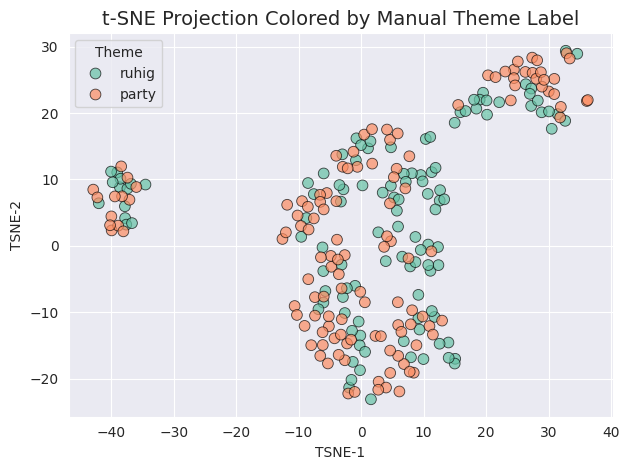
As mentioned earlier, I was not entirely happy with the matches. As a result, triaged the files into two groups. One which I experienced as quiet. Let’s see if we can confirm this very subjective impression in the data, even though we never told the model that these two groups exist.
We define the data to be plotted to include theme and filename.
Code
# Load manifest againmanifest = pd.read_csv("/app/data/raw-previews/explainabletrack_manifest.csv")labels = [f for f in manifest['theme']]tsne_df = pd.DataFrame({"x": embedding5[:, 0],"y": embedding5[:, 1],"theme": labels,"filename": filenames})
Overall, the data does not fit the perceived feature of “quietness.” The only think that is noticeable in the picture is a clustering of green points to the left and the bottom of the patch 2 and 3, respectively.
3.5.1 Intra- and inter-theme similarity
We can express this in numbers and calculate intra- and inter-theme similarity. The themes should be distinct and have little variation.
All of these numbers are very close to zero. This data backs the visual impression: The manual groups have nothing to do with the automatic selection. This explains why I was not satisfied. Features that I deemed important are somehow not in the data. Interesting.
3.6 Similarity analysis of single songs
Let’s study more how the model behaves with respect to a query. Our query song is Purple Rain - Prince.
My final playlist had this ordering
Luna - Bombay Bicycle Club.mp3
Purple Rain - Prince.mp3
Everybody Wants To Rule The World - Tears For Fears.mp3
Weakest match cosine similarity: 0.825
Best match: /opt/project/data/raw-previews/combined/Mesmerise - Temples.mp3 — cosine sim: 0.999
Again, we confirm that the automatic matching produced something different from my selection. Let’s compare all songs and also one which is completely off.
compare_songs("Purple Rain - Prince", "Everybody Wants To Rule The World - Tears For Fears", mp3tovecs)
compare_songs("Purple Rain - Prince", "Mr. Brightside - The Killers", mp3tovecs)
Similarity to Purple Rain - Prince: 0.933
compare_songs("Purple Rain - Prince", "Kiss from a Rose - Seal", mp3tovecs)
Similarity to Purple Rain - Prince: 0.990
3.6.1 Plotting single songs in TSNE plot
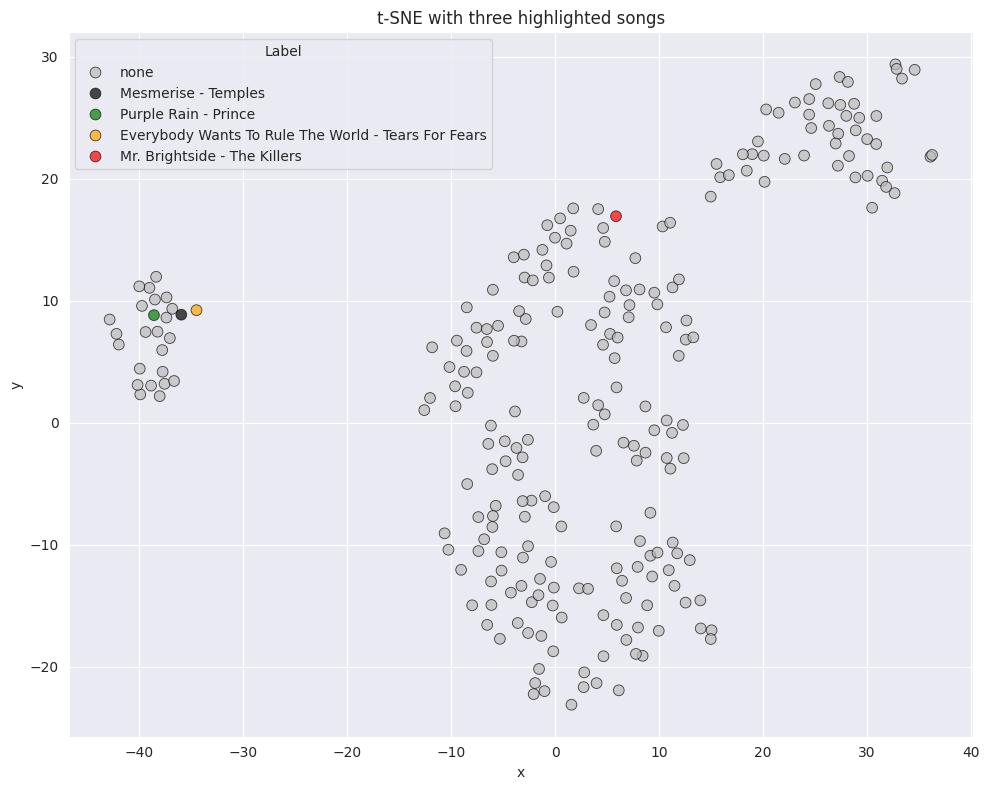
As a final step, we want to visualize what we have just expressed in numbers. How are the songs related to the plot?
Code
labels = ["none"] *len(filenames)songs = ["Purple Rain - Prince", "Mesmerise - Temples", "Everybody Wants To Rule The World - Tears For Fears","Mr. Brightside - The Killers", ]for i, f inenumerate(filenames):for song in songs:if song in f: labels[i] = songbreaktsne_df = pd.DataFrame({"x": embedding5[:, 0],"y": embedding5[:, 1],"theme": labels,"filename": filenames})
The picture confirms it again. Temples - Mesmerise is the best match. It should have been picked. It appears The nearby match Everybody Wants To Rule The World - Tears For Fears was not the closest match and only got taken because I interfered with the playlist creation.
4 Grad-CAM
Our Mp3ToVec network already tells us how close two songs are (cosine similarity), but not where that closeness comes from.
Are there any regions in the spectrogram that lead to the exact match? Which time–frequency zones triggered the network to declare “this query sounds like Song A (and not Song B)”. In the next section, we will look at Integrated Gradients, which observes down to pixel level. Grad-CAM offers a complementary, big-picture view.
4.1 Background
Grad-CAM works by examining the last convolutional layer, which acts as the model’s feature detector. We then use the gradient of the similarity score with respect to Song A to weight these feature maps.
Finally, we project the weighted activation maps back onto the spectrogram. This results in a coarse heatmap; red blobs where the CNN focused, and blank areas elsewhere.
In terms of interpretability, this allows a visual inspection, which goes beyond simple scores.
4.2 Implementation
from tensorflow.keras.models import load_modelimport tensorflow as tfmodel = load_model('/app/speccy_model', custom_objects={'cosine_proximity': tf.compat.v1.keras.losses.cosine_proximity })model.trainable =False;conv_layer = model.get_layer("separable_conv2d_3")
Now that we have defined a function to do GRAD-CAM for the full song. Let’s study the difference for song A and song B. We will get an answer which regions where more important to which song and which were identically important.
vec_A = mp3tovecs['/opt/project/data/raw-previews/combined/Mesmerise - Temples.mp3']vec_B = mp3tovecs['/opt/project/data/raw-previews/combined/Everybody Wants To Rule The World - Tears For Fears.mp3']x_query = mp3_to_slices('/app/data/raw-previews/combined/Purple Rain - Prince.mp3')
cam_A = full_song_grad_cam(model, x_query, vec_A, conv_layer)cam_B = full_song_grad_cam(model, x_query, vec_B, conv_layer)# we use signed log, as the songs are very close together.diff = tf.math.log((cam_A +1e-5) / (cam_B +1e-5))diff_clipped = tf.clip_by_value(diff, -3.0, 3.0)
Code
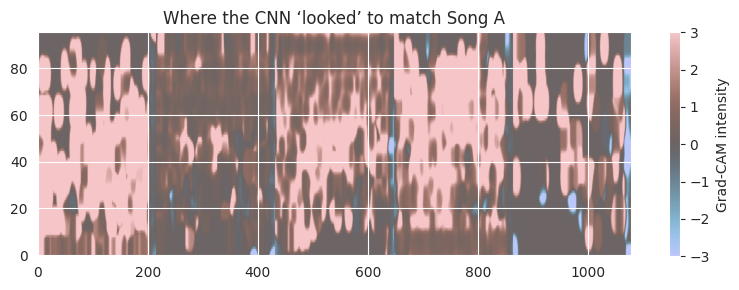
plt.figure(figsize=(8, 3))plt.imshow(diff_clipped, cmap="berlin", alpha=0.6, origin="lower", aspect="auto")plt.colorbar(label="Grad-CAM intensity")plt.title("Where the CNN ‘looked’ to match Song A")plt.tight_layout();plt.show()
Thanks to the clipping, the graph is easy to read. The Song had a lot more information, which made it similar to the query song.
Only at the very end are some blue spots. This could indicate that the spotify preview covers only the less relevant sections of the entire song for the particular comparison. Whereas I was listening to the full song. Song B seems better for the rhythm as the blue patches repeat.
We will dive deeper into this in the next section.
5 Integrated gradients
Why did the model prefer Song A over Song B? We know that the model turns spectrograms into 100-D vectors and ranks candidates using cosine similarity. That alone doesn’t tell us why one track got a higher score than another. To dig deeper, we use Integrated Gradients (IG). This method helps identify which parts of a spectrogram contribute most to the similarity score, that is which pixels or frequencies increase the score.
In contrast to Grad-Cam, we do not look at the feature level, but on input level through the entire network.
5.1 Background
IG works by comparing the actual input (the spectrogram) to a baseline input, typically silence.
We then gradually transition from the baseline to the real input by scaling the spectrogram with a factor \(\alpha\).
At each step, we compute the gradient of the output with respect to the input. When we average across all steps, we get the average contribution of each pixel.
In Pytorch we have the Captum library to directly do this. However, Deej-AI works on an older keras 2.13. We need to implement Integrated Gradients from scratch.
5.2 From scratch development of integrated gradients
5.2.1 Method for one slice
We define the integrated gradients for one slice
Let’s first clarify what we expect from the model
Luckily for a linear model \[f(x) = w^\top x + b\]
the Integrated Gradients have the closed-form
\[\mathrm{IG}(x) \;=\; (x - x_0)\,\odot\,w\]
We intend to use integrated gradients to check the impact on the cosine similarity score. Therefore, we need to integrate the L2 norm in the function. This has side effects in testing. We need to make the code modular to accommodate for this.
import tensorflow as tf# for testing, we will test on raw attribution without normalizationdef default_score_fn(preds, target_vec=None):if target_vec isnotNone: t = tf.reshape(tf.convert_to_tensor(target_vec, tf.float32), [-1])return tf.reduce_sum(preds * t, axis=-1)else:return tf.reduce_sum(preds, axis=-1)# we are interested on the effect of the cosine similarity score, therefore, we will need to do L2def cosine_score_fn(preds, target_vec): p = tf.nn.l2_normalize(preds, axis=1) t = tf.nn.l2_normalize(target_vec, axis=0)return tf.reduce_sum(p * t, axis=-1)# this is the function for one slicedef ig_one_slice( model, query_slice, target_vec, baseline_slice=None, steps=120, score_fn=default_score_fn):if baseline_slice isNone: baseline_slice = tf.zeros_like(query_slice, dtype=tf.float32)# make sure we work on f32 query_slice = tf.convert_to_tensor(query_slice, dtype=tf.float32) baseline_slice = tf.convert_to_tensor(baseline_slice, dtype=tf.float32)if target_vec isnotNone: target_vec = tf.convert_to_tensor(target_vec, dtype=tf.float32) target_vec = tf.reshape(target_vec, [-1])# Remove batch dim for interpolation start = tf.squeeze(baseline_slice, 0) # (96,216,1) end = tf.squeeze(query_slice, 0) # (96,216,1) alphas = tf.linspace(0.0, 1.0, steps)[:, tf.newaxis, tf.newaxis, tf.newaxis] interpolated = start + alphas * (end - start)# Compute gradientswith tf.GradientTape() as tape: tape.watch(interpolated) preds = model(interpolated) scores = score_fn(preds, target_vec) grads = tape.gradient(scores, interpolated) avg_grads = tf.reduce_mean(grads, axis=0) ig = (end - start) * avg_gradsreturn ig
Gradients can be noisy. We add some smoothing to get a better visual representation. We use a two-pass smoothing. First on the slice and later on the final output.
def test_for_ig_one_slice(): H, W =2, 3 flat_vals = np.arange(H * W, dtype=np.float32) # [0, 1, 2, 3, 4, 5] x = flat_vals.reshape((1, H, W, 1)) # shape: (1,2,3,1) x = tf.constant(x) x0 = tf.zeros_like(x) # shape: (1,2,3,1) w = tf.constant(flat_vals, dtype=tf.float32) # weights = [0,1,2,3,4,5] b = tf.constant(0., dtype=tf.float32)class LinearModel(tf.keras.Model):def__init__(self, w, b):super().__init__()self.w = wself.b = bdef call(self, inp): flat = tf.reshape(inp, [inp.shape[0], -1]) # (batch, D)# return a *vector* of length 1 so IG still works with a scalar outputreturn tf.matmul(flat, tf.expand_dims(self.w, 1)) +self.b model = LinearModel(w, b)# For this scalar-output model, set target_vec = [1.], so that# scores = f(interpolated) * 1 and grad(scores) = grad f. target_vec = np.array([1.], dtype=np.float32) ig_out = ig_one_slice(model, query_slice=x, target_vec=target_vec, baseline_slice=x0, steps=50) ig_out = ig_out.numpy().reshape(-1) closed_form = (x - x0).numpy().reshape(-1) * flat_vals # shape (6,) tf.debugging.assert_near(ig_out, closed_form, atol=1e-6)
test_for_ig_one_slice()
q.e.d.
5.2.3 Testing with real data
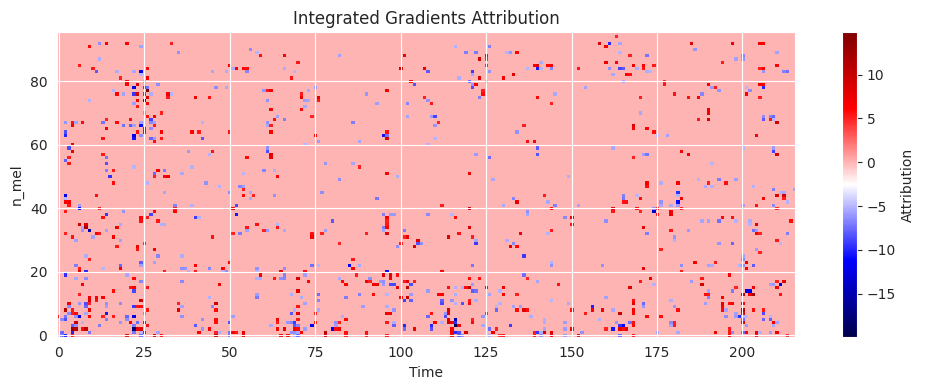
We will first examine the result for one slice, without any baseline or target vector. This produces the raw attribution of each pixel to the output value of the model.
from tensorflow.keras.models import load_modelmodel = load_model('/app/speccy_model', custom_objects={'cosine_proximity': tf.compat.v1.keras.losses.cosine_proximity })model.trainable =False
and method 2 that can be helpful if the embeddings are very close. The reason is that first taking the gradient and then calculating the difference amplifies the noise. This method has been introduced by Sundararajan et al. 2017.
The second method uses one scoring function, as described in the Captum interpretability library and aligned with contrastive explanation principles from Dhurandhar et al. 2018.
load our model: the one that produces the vectors.
the spectrogram of the query song. The analysis is built on it
the vector of song A, the best Match. We answer which parts of the query made it go to song A? we use song A as direction of analysis.
the vector of song B.
model = tf.keras.models.load_model("/app/speccy_model", custom_objects={'cosine_proximity': tf.compat.v1.keras.losses.cosine_proximity})model.trainable =False
query_slices = mp3_to_slices("/app/data/raw-previews/combined/Purple Rain - Prince.mp3")b_slices = mp3_to_slices("/app/data/raw-previews/combined/Everybody Wants To Rule The World - Tears For Fears.mp3")
import picklewithopen("/app/data/pickles/combined/mp3tovecs/mp3tovec.p", "rb") as f: mp3tovecs = pickle.load(f)vec_A = mp3tovecs['/opt/project/data/raw-previews/combined/Mesmerise - Temples.mp3']vec_B = mp3tovecs['/opt/project/data/raw-previews/combined/Everybody Wants To Rule The World - Tears For Fears.mp3']
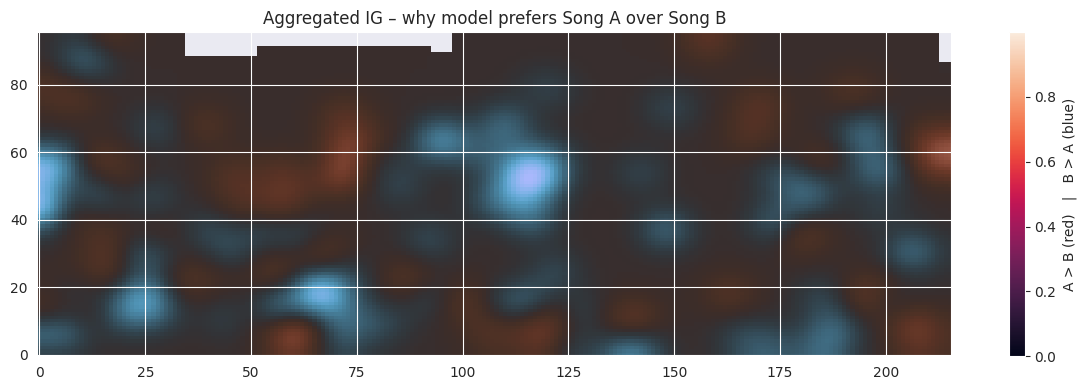
rgba_img, smoothed_mask = highlight_ig_regions(ig_contrast_method_1, percentile=99, sigma=5.0)plt.figure(figsize=(12, 4))plt.imshow(rgba_img, origin="lower", aspect="auto")plt.title("Aggregated IG – why model prefers Song A over Song B")plt.colorbar(label="A > B (red) | B > A (blue)")plt.tight_layout();plt.show()
There is not much insight that we can gain from this picture. We will see if the full song analysis can help. We define a function that assembles the full heatmap.
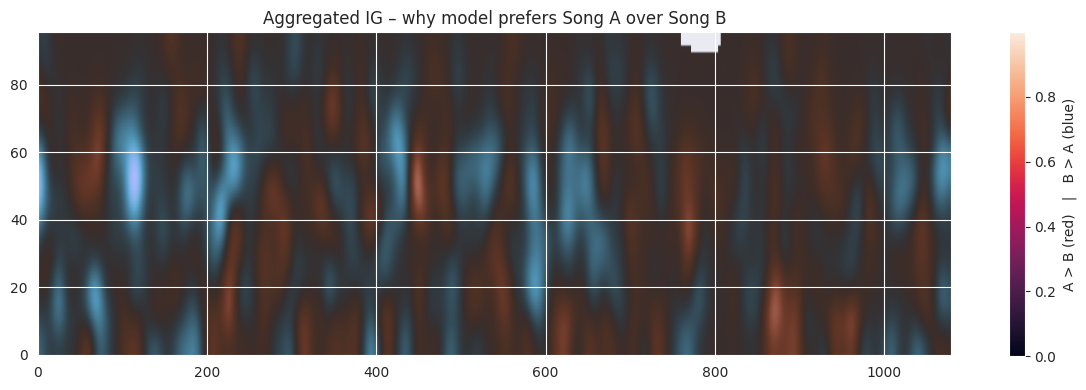
rgba_img, smoothed_mask = highlight_ig_regions(full_ig_method_1, percentile=99, sigma=8.0)plt.figure(figsize=(12, 4))plt.imshow(rgba_img, origin="lower", aspect="auto")plt.title("Aggregated IG – why model prefers Song A over Song B")plt.colorbar(label="A > B (red) | B > A (blue)")plt.tight_layout()plt.show()
The result is somewhat disappointing. Overall, the algorithm should have identified song B as the next song. There are only some red spots at the bottom in the lower frequencies.
Let’s again switch to a quantitative analysis and plot frequencies in bins.
Code
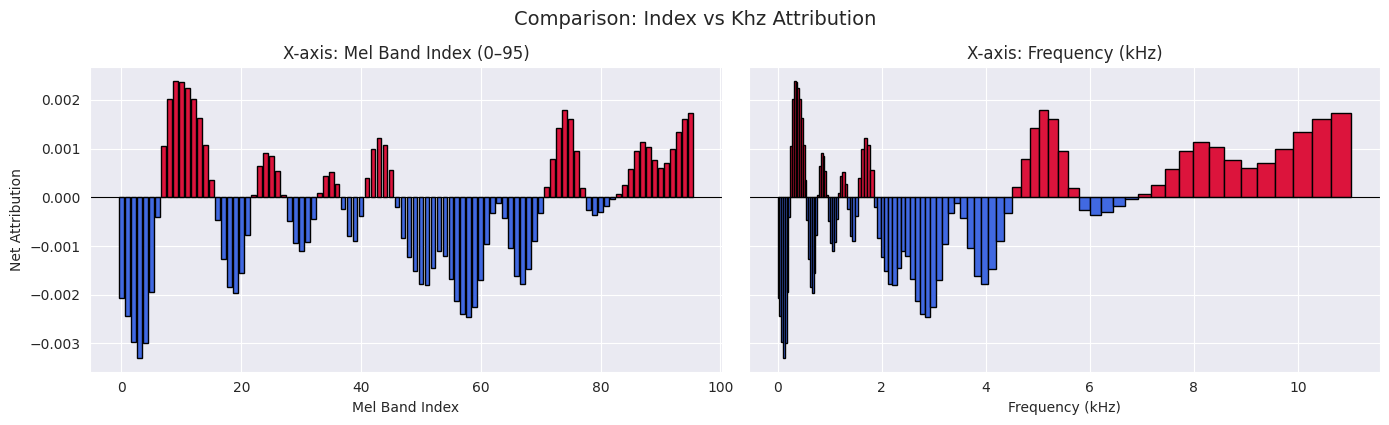
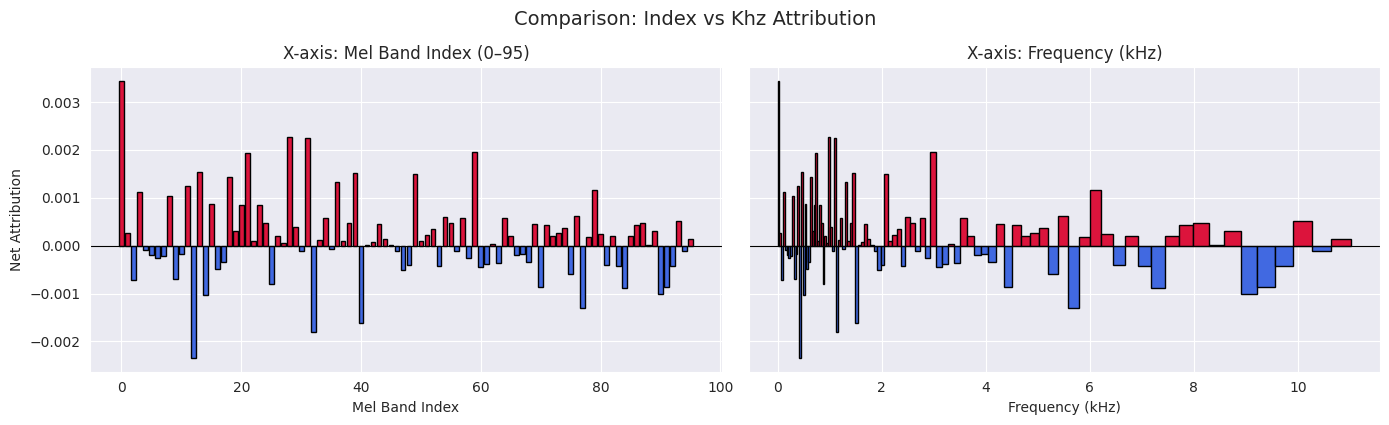
import librosaimport numpy as npimport matplotlib.pyplot as plt# Simulated IG data, for example,# Replace with your actual full_ig arraydef plot_ig_to_bins(full_ig): band = full_ig.sum(axis=1) sr =22050 num_bins =96# Mel frequency bin edges and centers mel_edges = librosa.mel_frequencies(n_mels=full_ig.shape[0] +1, fmin=0, fmax=sr /2) centres =0.5* (mel_edges[1:] + mel_edges[:-1]) /1000# in kHz mel_widths = np.diff(librosa.hz_to_mel(mel_edges))# Color by attribution sign colors = np.where(band >=0, "crimson", "royalblue") ig, axs = plt.subplots(1, 2, figsize=(14, 4), sharey=True) new_mel_edges = np.linspace(0, len(band), num_bins +1, dtype=int)# Aggregate original bins into fewer bins band_reduced = np.array([ band[new_mel_edges[i]:new_mel_edges[i +1]].sum()for i inrange(num_bins) ])# Compute centers of the new bins (in kHz) mel_centers_reduced = np.array([ (mel_edges[new_mel_edges[i]] + mel_edges[new_mel_edges[i +1]]) /2/1000for i inrange(num_bins) ])# Colors based on attribution sign colors = np.where(band_reduced >=0, "crimson", "royalblue")# --- Left: Simple index-based plot --- axs[0].bar(np.arange(len(band)), band, color=colors, edgecolor='black') axs[0].set_title("X-axis: Mel Band Index (0–95)") axs[0].set_xlabel("Mel Band Index") axs[0].set_ylabel("Net Attribution") axs[0].axhline(0, color='k', linewidth=0.8)# --- Right: Mel-scale-accurate plot --- plt.bar(mel_centers_reduced, band_reduced, width=np.diff(mel_edges[new_mel_edges]) /1000, color=colors, edgecolor='black') axs[1].set_title("X-axis: Frequency (kHz)") axs[1].set_xlabel("Frequency (kHz)") axs[1].axhline(0, color='k', linewidth=0.8) plt.tight_layout() plt.suptitle("Comparison: Index vs Khz Attribution", y=1.05, fontsize=14) plt.show()plot_ig_to_bins(full_ig_method_1)
The heatmap is transformed into two barcharts:
As mel band index (aligned with the vertical axis of the IG heatmap)
Converted to real-world frequency in kHz. We can see the nonlinear nature of the mel scale from this.
Both songs seem quite balanced in terms of attribution. It is not clear why the song was picked.
One potential reason: The embeddings are very close. Therefore, the noise in the gradient generation dominates. We can rerun the analysis with smoothing per slice.
The smoothing made the graphs easier to read. Attribution is very low. Song B is better in the low frequencies. Whereas a song A is better in the high frequencies. The graphs look nice, but there is a catch… Let’s look at method2 first.
5.3.3 Method 2
In the presence of weak gradients, method 2 suggests not calculating extra differences but using a single scoring function. This is done by making song B the baseline.
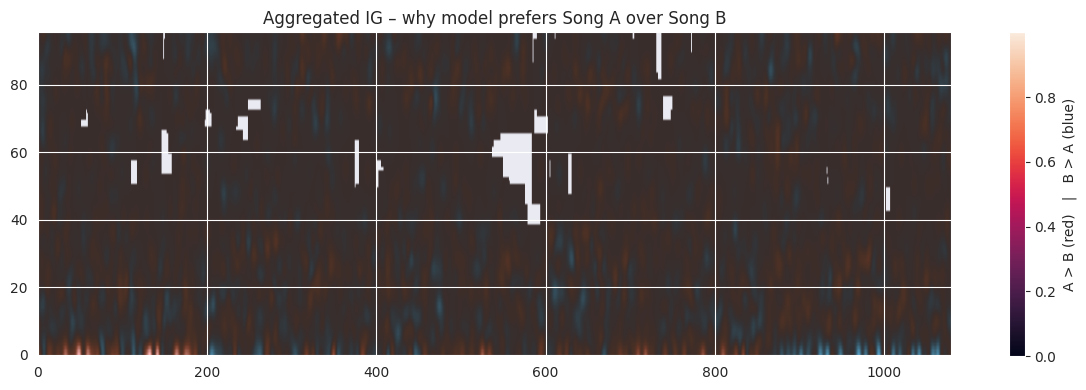
rgba_img, smoothed_mask = highlight_ig_regions(full_ig_method_2, percentile=95, sigma=2.5)plt.figure(figsize=(12, 4))plt.imshow(rgba_img, origin="lower", aspect="auto")plt.title("Aggregated IG – why model prefers Song A over Song B")plt.colorbar(label="A > B (red) | B > A (blue)")plt.tight_layout();plt.show()
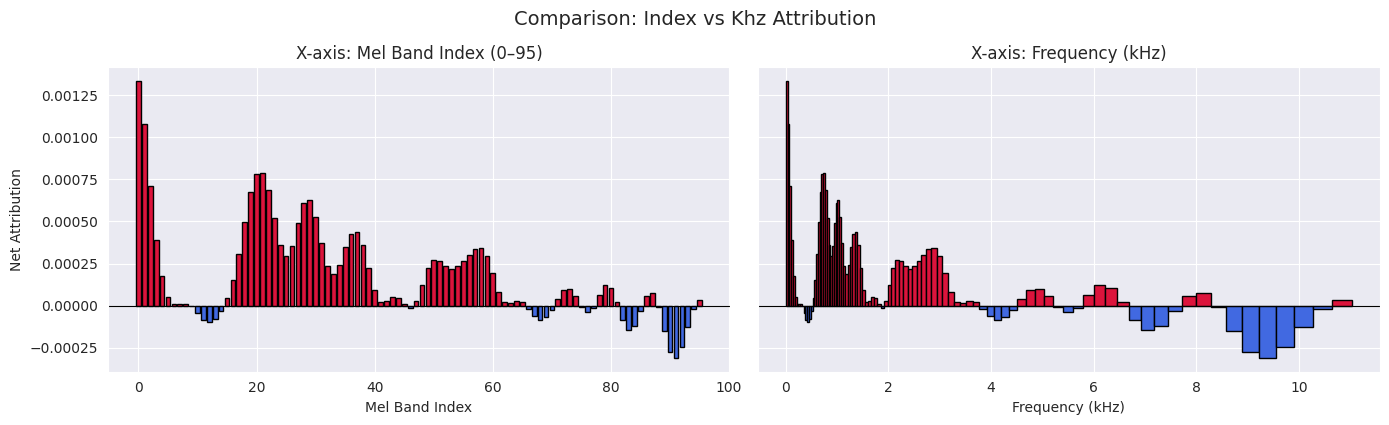
Now, Song A is favored in the lower frequencies, while Song B shows more influence in the upper bands.
5.4 Conclusion Method 1 vs. Method 2
One possible reason why Method 1 (subtracting filtered IGs) gives misleading results: If we apply Gaussian filtering before computing the difference, we might distort subtle but meaningful gradients. Since the raw attributions are weak overall, smoothing may disproportionately amplify or suppress regions — leading to an inaccurate contrast map. In fact, the raw IG maps for A and B look much more similar, and only diverge sharply after filtering.
This suggests that Method 2, which uses a single contrastive score function (sim(x, A) - sim(x, B)), is more stable and reliable in cases where the attribution signal is weak and gradients are low.
5.5 Interpretation
Assuming Method 2 provides the correct contrastive explanation, we can proceed with an interpretation. Overall, a Song A is a much better match in the low and mid-frequencies. These findings suggest that the song A’s similarity to the query (in this case, Purple Rain) is driven by features like kick drums, basslines, or low-mid instrumentation — all of which live in those bands.
Between 5 kHz and 9 kHz, we see increasing attribution for Song B. These frequencies often correspond to vocals, snares, cymbals, or presence-related features.
Interestingly, I listened to the tracks on a phone-conference headset, which emphasizes exactly that frequency range. So this auditory similarity aligns with what we hear — and validates the contrastive IG result.
6 Summary
6.1 What did we learn?
T-SNE analysis showed no clear clusters labeled “silent” or “party.” My subjective categories don’t appear to have a strong representation in the embedding space — at least not visibly
For two nearly identical songs:
T-SNE placed their embeddings close together in 2D space, confirming high similarity.
Grad-CAM revealed that Song A (the model’s top match) contained more regions that aligned well with the query’s audio features.
Integrated Gradients highlighted that Song A had stronger matches in the lower frequencies, whereas my personal impression focused on higher-frequency features where Song B was better.
6.2 Take away
Streaming platforms don’t just recommend popular songs; they can also suggest new or unknown music by analyzing the audio content directly through audio embeddings. While commercial systems use more advanced models and larger infrastructure, the core principles are the same as the methods demonstrated here. In addition, platforms incorporate collaborative filtering, user history, and social data to drive final recommendations.
What started as an experiment with a small CNN and a few audio clips turned into a concrete example of how machines “hear” music. Deep learning allows us to go beyond surface-level metadata like genre or artist, learning fine-grained acoustic patterns directly from the audio.
By exploring techniques like Grad-CAM, Integrated Gradients, and embedding visualization, we’ve opened a window into how machine learning models make decisions about music — and how we can interpret those decisions.
This type of analysis helps explain:
Why a recommendation “feels right”; even if you can’t explain it yourself
Why playlist transitions often make musical sense, even when songs come from different genres
If a basic model trained on a few spectrogram slices can already show interpretable behavior, imagine the scale and nuance of systems like Spotify, Apple Music, or TikTok.
This project isn’t just about “how one match happened.” It’s a glimpse into how modern recommendation systems think. Understanding these systems is important for a thoughtful usage.
Like this post? Get espresso-shot tips and slow-pour insights straight to your inbox.